| News / Science News |
Scientists translate brain signals into speech sounds
Scientists used brain signals recorded from epilepsy patients to program a computer to mimic natural speech — an advancement that could one day have a profound effect on the ability of certain patients to communicate.
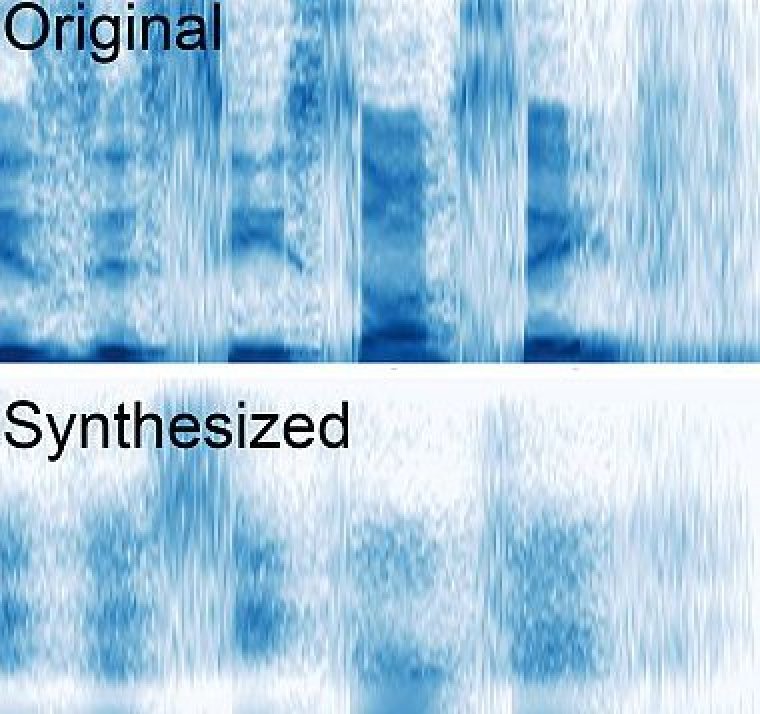
Patients were asked to speak the complete sentence (top), and the recorded brain activity was used to create a synthesized version of the same sentence (bottom). Photo: Chang lab
In this study, speech scientists and neurologists from University of California, San Francisco (UCSF) recreated many vocal sounds with varying accuracy using brain signals recorded from epilepsy patients with normal speaking abilities.
The patients were asked to speak full sentences, and the data obtained from brain scans was then used to drive computer-generated speech. Furthermore, simply miming the act of speaking provided sufficient information to the computer for it to recreate several of the same sounds.
The loss of the ability to speak can have devastating effects on patients whose facial, tongue, and larynx muscles have been paralyzed due to stroke or other neurological conditions. Technology has helped these patients to communicate through devices that translate head or eye movements into speech.
Because these systems involve the selection of individual letters or whole words to build sentences, the speed at which they can operate is very limited. Instead of recreating sounds based on individual letters or words, the goal of this project was to synthesize the specific sounds used in natural speech.
Current technology limits users to, at best, 10 words per minute, while natural human speech occurs at roughly 150 words/minute.
The researchers took a two-step approach to solving this problem. First, by recording signals from patients’ brains while they were asked to speak or mime sentences, they built maps of how the brain directs the vocal tract, including the lips, tongue, jaw, and vocal cords, to make different sounds. Second, the researchers applied those maps to a computer program that produces synthetic speech.
Volunteers were then asked to listen to the synthesized sentences and to transcribe what they heard. More than half the time, the listeners were able to correctly determine the sentences being spoken by the computer.
By breaking down the problem of speech synthesis into two parts, the researchers appear to have made it easier to apply their findings to multiple individuals. The second step specifically, which translates vocal tract maps into synthetic sounds, appears to be generalizable across patients. (National Institutes of Health)
YOU MAY ALSO LIKE